هل يمكن الوثوق بكاشف الذكاء الاصطناعي هذا؟
أدق كاشف للذكاء الاصطناعي وفق معيار MGTD
معيار MGTD (ICAIE, 2025)– أكبر وأقوى معيار لكواشف الذكاء الاصطناعي، يتكون من 15 مجموعة بيانات مختلفة. جمع الباحثون أكثر من 2 مليون عينة وقاسوا جودة كواشف الذكاء الاصطناعي الشهيرة. حصد It's AI المركز الأول مع أكثر من 92% ROC-AUC.
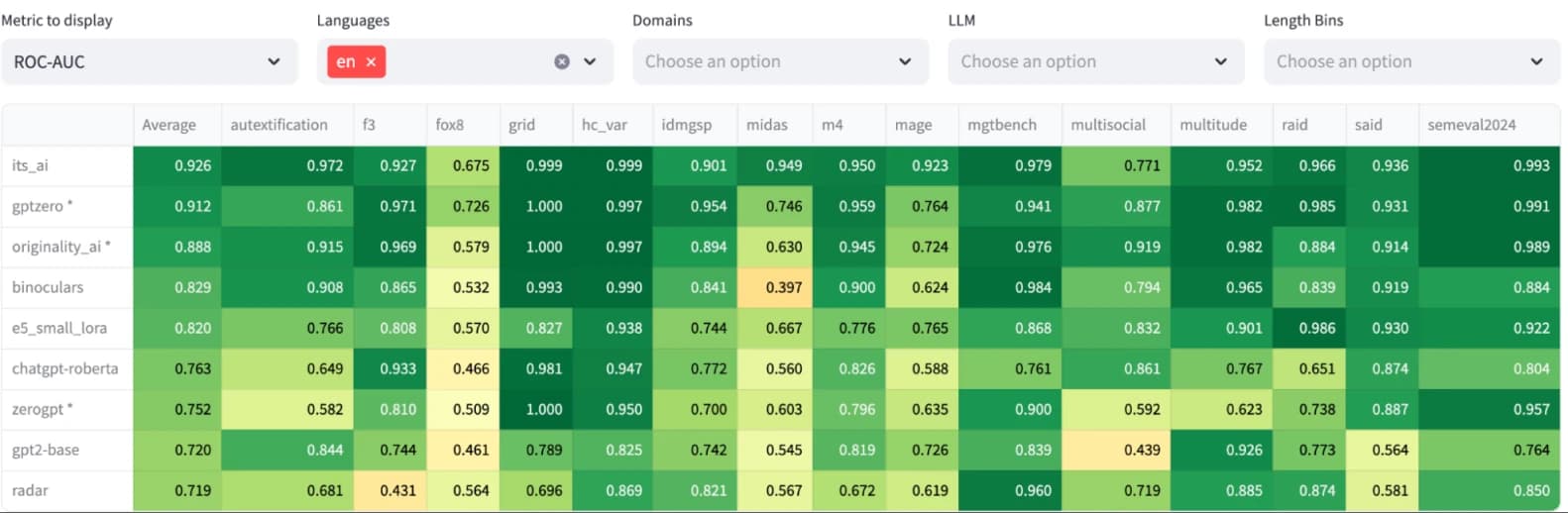
RAID
RAID (ورقة ACL، 2024) هو معيار كبير آخر لتقييم كواشف الذكاء الاصطناعي، وإن كان قديمًا بعض الشيء لأنه نُشر في أغسطس 2024. يحتوي على أكثر من 600 ألف عينة نصية مولدة بواسطة 11 نموذجًا مختلفًا عبر 8 مجالات في قسم الاختبار.
لقد قدمنا It's AI في لوحة المتصدرين الرسمية وحصلنا على دقة 98.3%.
دقة 99% على GRiD وHC3 وGhostBuster
مجموعة بيانات GPT Reddit (GRiD) تتألف من أزواج سياق وسؤال مأخوذة من Reddit، مع إجابات يكتبها البشر وأخرى يولدها ChatGPT.
إن HC3 (مجموعة مقارنة إجابات البشر وChatGPT) تتضمن ما يقرب من 40 ألف سؤال وإجاباتها البشرية وChatGPT المتقابلة.
إن GhostBusters تستخدم نموذج GPT-3.5-turbo لإنتاج نصوص في مجالات الكتابة الإبداعية والأخبار ومقالات الطلاب.
في المتوسط على هذه المجموعات الثلاث حقق It's AI دقة 99.1% ودرجة F1 بنسبة 96%، متفوقًا على جميع الكواشف المذكورة في الأوراق (لم تُقيَّم الكواشف التجارية هناك).
معدل إيجابي خاطئ 0.8% على ASAP 2.0
معدل الإيجابي الخاطئ (FPR) هو مقياس مهم آخر يجب مراعاته عند الحديث عن كشف الذكاء الاصطناعي. يمثل عدد النصوص المكتوبة فعليًا من قبل البشر التي سيتم تصنيفها بالخطأ على أنها مولدة بالذكاء الاصطناعي.
انخفاض FPR مهم بشكل خاص للتعليم، حيث يفضل فقدان بضعة أعمال مولدة بالذكاء الاصطناعي بدلاً من اتهام الطلاب الذين كتبوا النص بأنفسهم بشكل خاطئ. لهذا السبب قررنا بالإضافة إلى المعايير السابقة قياسه على مجموعة بيانات ASAP 2.0.
تتكون مجموعة ASAP 2.0 من 25,000 مقال إقناعي للطلاب مأخوذ من اختبارات الكتابة الموحدة. تم اختيار المقالات لتعظيم كمية المعلومات الديموغرافية المتاحة لكل كاتب بما في ذلك حالة تعلم اللغة الإنجليزية (ELL) والخلفية الاقتصادية (محرومة أم لا) وحالة الإعاقة والعرق/الإثنية والجنس والمستوى الدراسي.
ظهر أن It's AI يخطئ في تصنيف هذه النصوص في أقل من 1% من الحالات مع FPR يساوي 0.8%.
كاشف الذكاء الاصطناعي بالعربي — تقييم الدقة
يدعم It's AI كشف وفحص الذكاء الاصطناعي بالعربي بالكامل. قمنا بقياسه على عدة معايير عربية ويمكنك الاطلاع على نتائجها أدناه:
ASJP – أوراق علمية. تحتوي هذه المجموعة على نص عربي مولد آليًا عبر طرق توليد متعددة ونماذج لغوية كبيرة (LLMs). تم إنشاؤها كجزء من ورقة البحث "البصمة العربية للذكاء الاصطناعي: التحليل الأسلوبي وكشف نصوص نماذج اللغة الكبيرة".
XL-SUM– أخبار عربية. XLSum هي مجموعة بيانات شاملة ومتنوعة تتكون من 1.35 مليون زوج من المقالات والملخصات المشروحة مهنيًا من BBC، تم استخراجها باستخدام مجموعة من القواعد المصممة بعناية. تغطي المجموعة 45 لغة بما في ذلك العربية تتراوح من منخفضة إلى عالية الموارد، والتي لا تتوفر لكثير منها مجموعة بيانات عامة حاليًا. XL-Sum تجريدية للغاية وموجزة وعالية الجودة، كما يشير التقييم البشري والجوهري.
It's AI — دقة لا مثيل لها يمكنك الوثوق بها
بشكل عام، أصبح It's AI نموذجًا جديدًا في مستوى الأفضل (SOTA) على معيار MGTD، متفوقًا على كواشف الذكاء الاصطناعي الأخرى وأظهر أداءً مميزًا على معايير RAID وGRiD وHC3 وGhostBuster وASAP 2.0 وASJP وXL-SUM، مما يثبت اتساقه وموثوقيته.
ضمن أصالة عملك
