Can I trust this tool?
The most accurate AI-detector according to MGTD benchmark
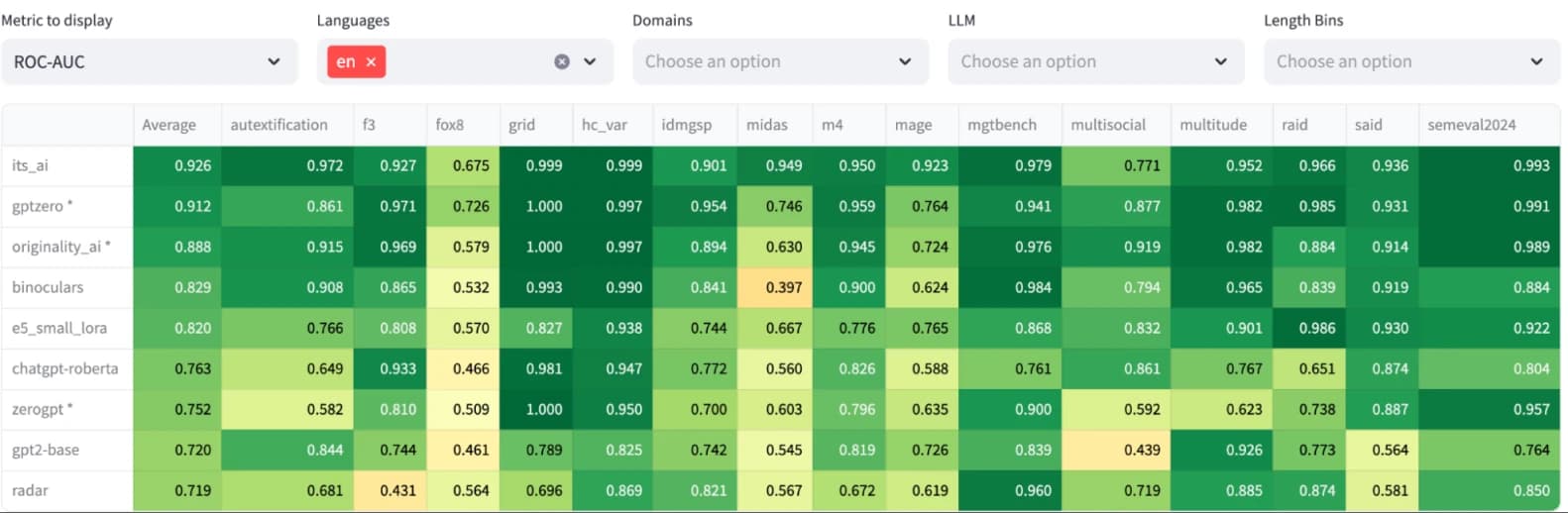
MGTD benchmark (ICAIE, 2025)– the biggest and most robust benchmark for AI checkers, consisting of 15 different datasets. Authors collected over 2M samples and measured quality or popular AI detectors. It's AI took the first place with over 92% Roc-Auc score.
RAID
RAID (ACL paper, 2024) is another big benchmark for AI detectors evaluation, though already a bit outdated, because it was published in August 2024. It contains over 600k text samples generated by 11 different models across 8 domains in its test split.
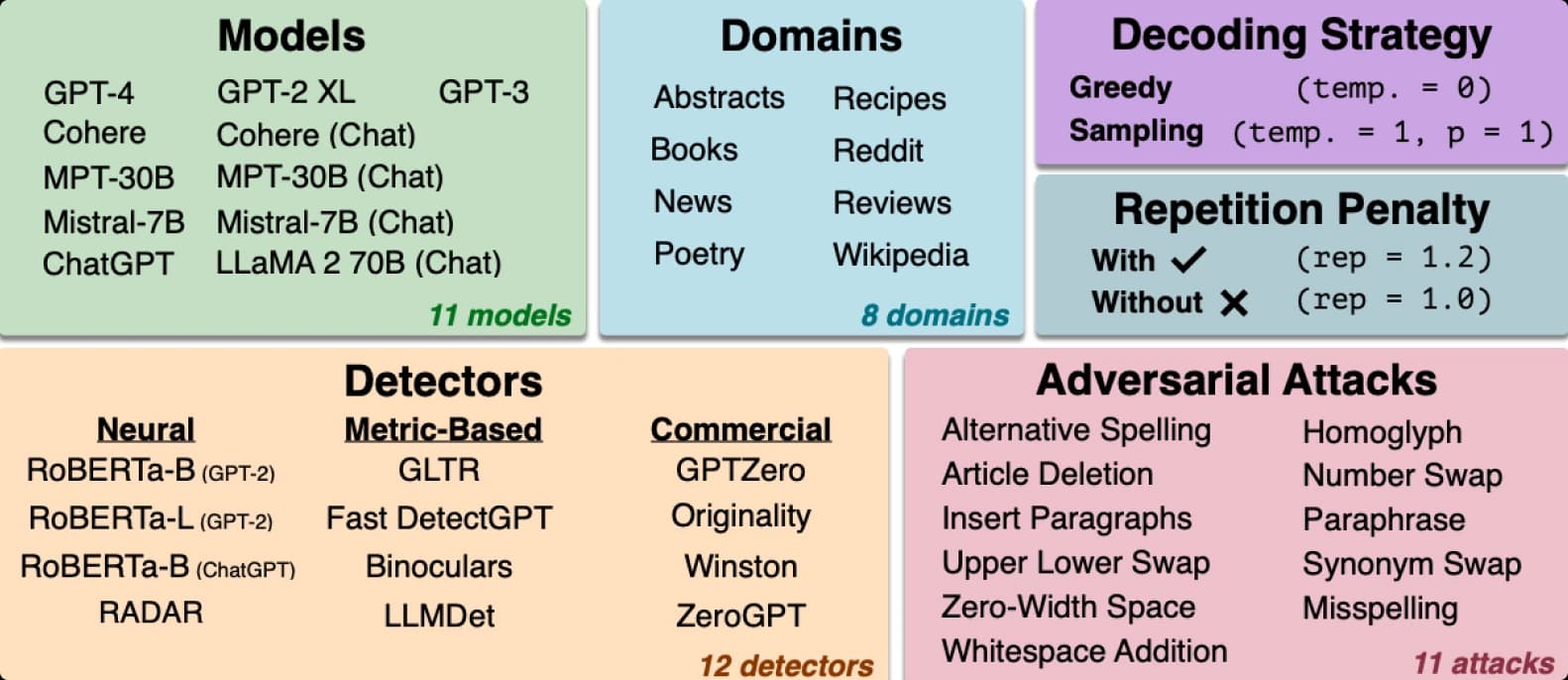
We've submitted It's AI into their official leaderboard and got 98.3% accuracy.
99% accuracy on GRiD, HC3, GhostBuster
GPT Reddit Dataset (GRiD) consists of context-prompt pairs sourced from Reddit, featuring responses generated by humans and generated by ChatGPT.
The HC3 (Human ChatGPT Comparison Corpus) dataset consists of nearly 40K questions and their corresponding human/ChatGPT answers.
The GhostBusters dataset leverages the GPT-3.5-turbo model for generating texts in the domains of creative writing, news, and student essays.
On average on these 3 datasets It's AI took 99.1% accuracy and 96% f1-score, outperforming all considered in the papers detectors (commercial detectors weren't scored there).
0.8% False Positive Rate on ASAP 2.0
False Positive Rate (FPR) is a another important metric that we should consider when we talk about AI detection. It represents how many texts that are actually written by human will be by mistake flagged as AI.
Low FPR is especially critical for education, when it's better to miss a couple AI generated works instead of false accusing students, who wrote text by themselves. That's why in addition to previous benchmarks we decided to measure it on the education-related ASAP 2.0 dataset.
The ASAP 2.0 corpus comprises 25,000 persuasive students' essays taken from standardized writing tests. Essays were selected to maximize the amount of demographic information available for each writer including English Language Learning (ELL) status, economic background (disadvantaged or not), disability status, race/ethnicity, gender, and grade level.
It's AI appeared to misclassifying these texts in less than 1% cases with FPR equal to 0.8%.
Arabic language evaluation
It's AI fully support AI detection in arabic language. We've measured it on several arabic benchmarks and you can find their results below:
ASJP – scientific papers. This dataset contains machine-generated Arabic text across multiple generation methods, and Large Language Model (LLMs). It was created as part of the research paper "The Arabic AI Fingerprint: Stylometric Analysis and Detection of Large Language Models Text".
XL-SUM– Arabic news. XLSum is a comprehensive and diverse dataset comprising 1.35 million professionally annotated article-summary pairs from BBC, extracted using a set of carefully designed heuristics. The dataset covers 45 languages including Arabic ranging from low to high-resource, for many of which no public dataset is currently available. XL-Sum is highly abstractive, concise, and of high quality, as indicated by human and intrinsic evaluation.
It's AI — Unmatched Accuracy you can trust
Overall, It's AI became a new SOTA (State-of-the-art) model on MGTD benchmark, outperforming other AI detectors and demonstrated a significant performance on RAID, GRiD, HC3, GhostBuster, ASAP 2.0, ASJP and XL-SUM datasets, proving its consistency and reliability.
Ensure originality of your work
